The first Mongolian IT engineering community meet up

November 24, 2018. I had the chance to be a part of an event called MITEC (Mongolian Information Technology Engineering Community). This event was the first IT engineers’ meet up #1.
I am not a tech expert or an IT engineer but I will try my best to explain what happened and what I found helpful from the event. There were 6 lecturers who got together to organize this event, whom they want to call themselves as “JUST ENGINEERS”. Which is kind of interesting because most of the events I took part in was all had a name or logo of the organization or the organizing committee on everything they make for the event. But this event was so different because they had absolutely nothing! Well except the lecturers’ names of course. The main reason for organizing this event was to share their experiences and know-how about using or making technologies and program with other fellow engineers who have faced or are facing the same problems.
Okay, now I will start writing about a little bit of definition about these topics and the mentioned contents.
The first speaker was Amarbayar Amarsanaa who works as a Sr Site Reliability Engineer at GitLab Inc, discussed Difference between DevOps and SRE and why SRE is becoming TREND.

From my understanding, DevOps is an abbreviation of Development and Operations which can help software organizations innovate faster and be more responsive to business needs. Comparing to the old times when Development and Operations where divided concept, both sides had no synergy between themselves and used to have clashes in case of problems concerning with the results. Clashes lead to engineers quitting jobs, misunderstandings inside the team and more. However, DevOps, the mix of both sides promotes collaboration between developers and operations which improves the quality of software development and more frequent software releases.
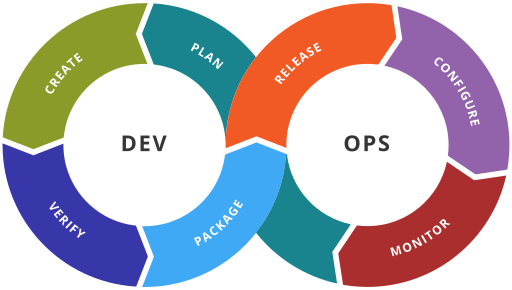
On the other hand, SRE (Site Reliability Engineer) was built because of the constant increasing scale of users, programs, and business’, challenging the capacity of handling companies. Site reliability engineering seeks to improve the reliability of currently operating the software while minimizing the work involved in its upkeep. It also works as a prepared side, which calculates the expected usage increase of particular peaks, depending on the statistics of previous years. For example on “Black Friday” where many people use amazon.com actively to buy items online, server droppings are bound to happen but would be no drops of servers during the peak thanks to preparation.

And why is it a TREND?
Since companies started making DevOps as an automatic system, it had nothing much left to do. And SRE works as more like a maintenance, and improvement solution, so if something happens with the program, they react faster, fixes the problem in a blink of an eye because they are specialized with it. As a result, SRE started acting as a consultant, which companies could ask advice from them instead of trying to solve it themselves.
In conclusion: People who are facing the following problems, work in accordance with this system.
Try DevOps — Automate DevOps — Become SRE
The second speaker was Purevbazar Purevjav, Founder @Fibo Global, discussed “What’s up in the Cloud. Introduction to Cloud Computing services. Brief history, Benefits & Drawbacks, Vendor comparisons, How to make an adoption into the Cloud and typical use cases”.

Cloud which is a general term for the delivery of hosted services over the Internet. Cloud computing enables companies to consume a compute resource, such as a virtual machine (VM), storage or an application, as a utility — just like electricity — rather than having to build and maintain computing infrastructures in house.
Cloud has 2 main types which are a public and private cloud.
- The public cloud market is led by a few key players, including Amazon Web Services (AWS), Microsoft Azure and Google Cloud Platform. These providers deliver their services over the internet and use a fundamental pay-per-usage approach. Each provider offers a range of offerings oriented toward different workloads and enterprise needs.
- Currently, businesses can develop a Private Cloud system, designed for their particular needs. These Private Clouds store, and can share sensitive data. Staff “can” also use, Public Clouds, or a combination of the two called a Hybrid Cloud. Much of the modern business consumer market relies on Cloud services. Private Cloud Computing is currently used for email, to log-in on online gaming platforms, and for Facebook.
He explained that Cloud has benefits like:
- SLA (Service Level Agreement) which categorizes the services and documents it,
- Low Cost which is instead of buying a server machine and paying for its maintenance they just have to pay for a usage fee when the program is active,
- Elasticity and Flexibility means exactly what it MEANS, you can add categories or extensions for the program in five minutes without making it a problem and just like what happens on Black Friday, you can maximize or minimize the scale and capacity of the program easily especially on amazon web servers,
- Security is at it’s best because bigger servers that cloud is based on, performs according to the regulations of US meaning it is secure than any other servers,
- Innovation because of the Cloud, people will have the freedom to do things they could not before. They will have the freedom to experiment, to assess, and to locate data and information from a variety of sources.
The third speaker was Ochir Sanjaadorj, Sr Web Developer, Arcane Technologies, discussed “Best practices on organizing and managing your cloud compute instances and doing backups. This session will focus on EC2(Elastic Computing Cloud) on AWS(Amazon Web Server)”.

AWS is a cloud computing platform from Amazon that provides customers with a wide array of cloud services. Amazon bills customers for AWS based on their usage of the various Services. Thankfully, after signing up for AWS,you can use some of the free tier services free for a YEAR. So during that time, you could try them. And when the trail is over, you have to pay on services you demand from the server.
- One of the services people usually use is EC2 which provides storage, processing, and Web services to customers. It is a virtual computing environment, that enables customers to use Web service interfaces to launch instances with a variety of operating systems, load them with your custom applications, manage your network’s access permissions, and run your image using as many or few systems as you need.
- Amazon charges money for the size of the file on S3( Simple Storage Service) which has limits to 5G. But you can solve the problem by making different volumes in different categories.
- Tagging your Amazon resources helps you to recover or backup your data. A tag is a label that you assign to an AWS resource. Each tag consists of a key and an optional value, both of which you define.
- A Security group acts as a virtual firewall that controls the traffic for one or more instances. When you launch an instance, you can specify one or more security groups; otherwise, we use the default security group.
- Amazon EC2 uses public–key cryptography to encrypt and decrypt login information. Public–key cryptography uses a public key to encrypt a piece of data, such as a password, then the recipient uses the private key to decrypt the data. The public and private keys are known as a key pair. So try not to forget your key pair. Without it, you can not use the same image again. As a part of security, you can not download the same key pair from AWS, so you have to save it from the first place.
The fourth speaker was Erdenezul Batmunkh, Sr Fullstack Developer at Shine Research, discussed with us about “Implementing CI on GitLab, deploying to Docker containers and scaling with Kubernetes”.

- CI(Continuous Integration) is more like a support system of GitLab(DevOps lifecycle application that covers the whole integration and activities related to Development and Operations as I explained above). CIis the process of automating the build and testing of code every time a team member commits changes to version control. It also notifies when you forgot or left to do the tests or so.
- CD(Continuous Delivery) is the process to build, test, configure and deploy from a build to a production environment. After all the building and testing is done, you have to produce the program. That’s where CD comes into integration.
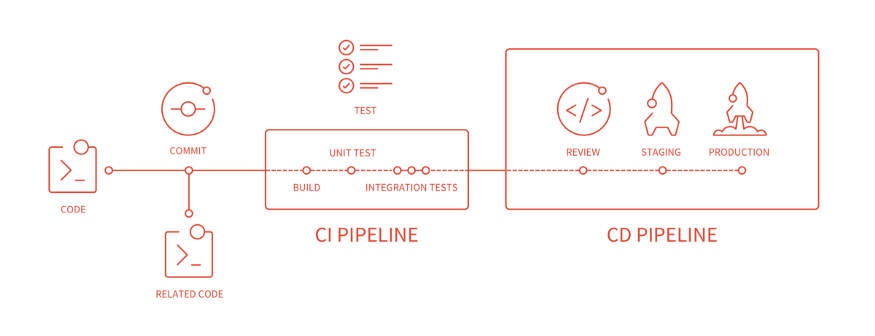
When something goes wrong, there will be a red Xs on your GitLab to do list. And you can check what exactly is wrong by checking those red marks.
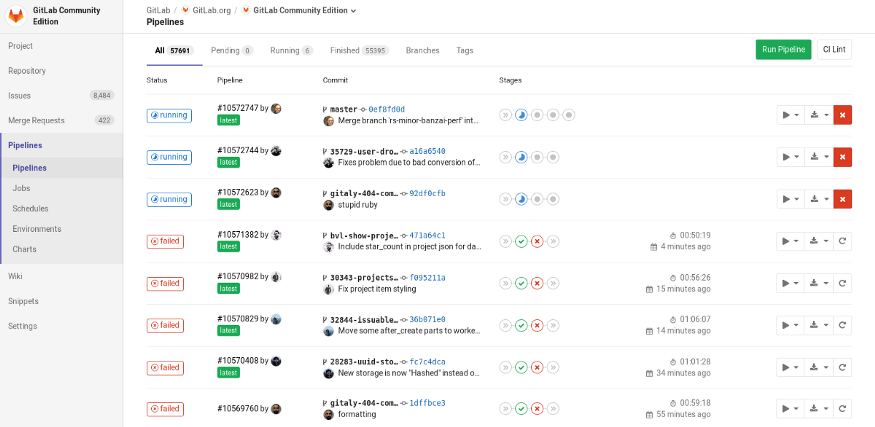
Docker container is an open-source software development platform that packages applications in “containers,” allowing them to be portable among any system running the Linux operating system (OS). Kubernetes is a portable, extensible open-source platform for managing containerized workloads and services, that facilitates both declarative configuration and automation. Kubernetes has a number of features such as a container platform, a microservices platform(which will be explained next), a portable cloud platform and a lot more.
In conclusion, developers make lots of mistakes on building a program or application and faces lots of difficulties starting from miscommunications with teammates to making mistakes with the smallest details during coding. And GitLab helps to improve this situation by saving time and effort with every little process.
The fifth speaker is Tuvshinbayar Davaa, Engineer, National Data Center, discussed with us about Why planning for disasters, having well-tested recovery processes and implementing proactive monitoring solutions help with smoother incident management, in other words, Incident Management.

He explained, “there will be problems even though you planned it thoroughly. SLA management should be planned well enough to carry on the services in accordance with the agreement. If it is not planned well, the company will lose its customers. Resulting revenue loss, the company will go bankrupt. Things will not go as planned with 100%. So as a risk management, it has to be 99.8% fulfillment and 0.2% error budget (calculated risk of making mistakes).”
So when is the right time to declare incidents, what do you count as an incident? It is visible to the users and clients, service interruptions, and a data availability and loss. The causes of incidents are new releases and updates of the program, traffic and disaster. Related management differs in accordance with the client numbers. Incident response should go as stated in given regulations. And what if we can not manage the incidents? You have to check what is the problem and try not to do that again. Plus, he also mentioned that most useful application on managing the incidents are #OpsGenie and #ChatOps.
FIBO Global is a cloud solution provider & consulting company specializing in Amazon Web Services, Microsoft Azure, Google Cloud, DevOpsmethodologies & tools. Found in 2017, actively working on cloud-related systems. They fully use all those cloud-based systems and regulations I mentioned above. Well, of course, the cloud system is nothing new around the world but here in Mongolia, we do not WHAT exactly it is even though we use it in our everyday life. And one of the founders of this company, Ganjiguur was the last speaker of this event, explained about “Lessons learned from breaking a monolithic application into microservices. Benefits of Decoupling.”

Microservices is basically a self-contained process that provides a unique business capability. Meaning that if one microservice drops you can change the one that is having troubles operating instead of changing the entire application consists of many microservices. The company he used to work wasted lots of time during the integration of services. Mostly spent on downloading or uploading the related information. By using microservices it saves time to integrate and update the software.
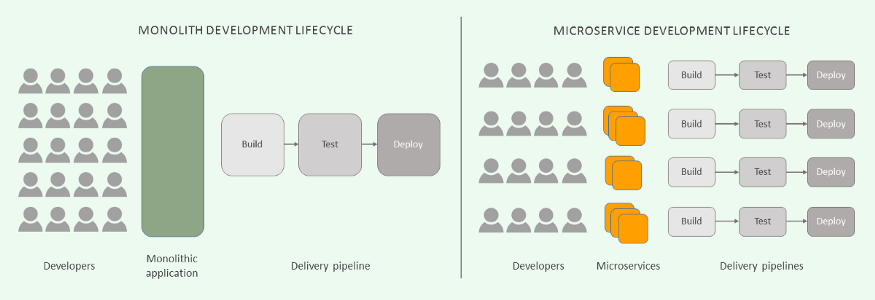
Decoupled, or decoupling is a state of an IT environment in which two or more systems somehow work or are connected without being directly connected. It is a type of IT operational environment where systems, elements or components have none or very little knowledge about the other components.
In the end, there were number of START-STOP-CONTINUE ideas I had and probably other delegates had in their mind.
Firstly, Start — planning the event more efficiently.
- Speakers had so many ideas that they did not really presented their topics in given time.
- Venue had so many difficulties such as broken screen, and slow internet.
- Organizers should choose a bigger space hall for the event in the future because there will be more people interested in attending this event.
- Needs Q/A time.
Stop- Prepare complex speech that is fit for the given time.
- Speakers speech was too long
- Too many Demos
Continue — They should continue organizing this event eventually.
- Improving the qualities, explaining the difficulties
- Doing Practical workshops
- Demos
- Sharing their experiences
- Choose interesting yet wide range of topics
In conclusion, all the lecturer mentioned their faced difficulties of these mentioned topics above plus how they solved their problems. If all the IT engineers and developers would annually meet up with each other throughout the year to discuss their problems, in other words, do the DevOps in their life, I think there will be no problem with the improvement of Mongolia’s IT future.